
EAST、PixelLink、TextBoxes++、DBNet、CRNN…你都掌握了吗?一文总结OCR必备经典模型(二)
机器之心 2023-07-30 12:40 发表于北京
以下文章来源于机器之心SOTA模型,作者机器之心SOTA模型

机器之心专栏
本专栏由机器之心SOTA!模型资源站出品,每周日于机器之心公众号持续更新。 本专栏将逐一盘点自然语言处理、计算机视觉等领域下的常见任务,并对在这些任务上取得过 SOTA 的经典模型逐一详解。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及 API 等资源。
本文将分 3 期进行连载,共介绍 17 个在OCR任务上曾取得 SOTA 的经典模型。
- 第 1 期:CTPN、TextBoxes、SegLink、RRPN、FTSN、DMPNet
- 第 2 期:EAST、PixelLink、TextBoxes++、DBNet、CRNN、RARE
- 第 3 期:ABCNet、Deep TextSpotter、SEE、FOTS、End-to-End TextSpotter
您正在阅读的是其中的第 2 期。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及 API 等资源。
第 1 期回顾:CTPN、TextBoxes、SegLink、RRPN、FTSN、DMPNet…你都掌握了吗?一文总结OCR必备经典模型(一)
本期收录模型速览
| 模型 | SOTA!模型资源站收录情况 | 模型来源论文 |
| EAST | https://sota.jiqizhixin.com/project/east 收录实现数量:6 支持框架:PyTorch、TensorFlow等 |
EAST: An Efficient and Accurate Scene Text Detector |
| PixelLink | https://sota.jiqizhixin.com/project/pixellink 收录实现数量:3 支持框架:TensorFlow |
Detecting Scene Text via Instance Segmentation |
| TextBoxes++ | https://sota.jiqizhixin.com/project/textboxes-_1 收录实现数量:4 支持框架:PyTorch、TensorFlow |
TextBoxes++: A Single-Shot Oriented Scene Text Detector |
| DBNet | https://sota.jiqizhixin.com/project/dbnet_1 收录实现数量:4 支持框架:PyTorch、TensorFlow等 |
Real-time Scene Text Detection with Differentiable Binarization |
| CRNN | https://sota.jiqizhixin.com/project/crnn-4 收录实现数量:4 支持框架:PyTorch、TensorFlow等 |
An End-to-End Trainable Neural Network for Image-based Sequence Recognition and ItsApplication to Scene Text Recognition |
| RARE | https://sota.jiqizhixin.com/project/rare 收录实现数量:3 支持框架:PyTorch、TensorFlow |
Robust Scene Text Recognition with Automatic Rectification |
光学字符识别(Optical Character Recognition,OCR)是指对文本资料进行扫描后对图像文件进行分析处理,以获取文字及版面信息的过程。一般来说,在获取到文字之前需要首先对文字进行定位,即执行文本检测任务,将图像中的文字区域位置检测出来;在找到文本所在区域之后,对该区域中的文字进行文字识别。文字识别就是通过输入文字图片,然后解码成文字的方法。OCR解码是文字识别中最为核心的问题。传统技术解决方案中,分别训练文本检测和文字识别两个模型,然后在实施阶段将这两个模型串联到数据流水线中组成图文识别系统。
对于文本检测任务,主要包括两种场景,一种是简单场景,另一种是复杂场景。简单场景主要是对印刷文件等的文本检测,例如像书本扫描、屏幕截图,或是清晰度高、规整的照片等。由于印刷字体的排版很规范,背景清晰,现在的检测、识别技术已经很成熟了,检测的效果都比较好。通过利用计算机视觉中的图像形态学操作,包括膨胀、腐蚀基本操作,即可实现简单场景的文字检测。复杂场景主要是指自然场景,由于光照环境以及文字存在着很多样的形式,例如灯箱广告牌、产品包装盒、设备说明、商标等,存在角度倾斜、变形、背景复杂、光线忽明忽暗、清晰度不足等情况,这时要将文本检测出来难度就比较大了,此时主要考虑引入深度学习模型进行检测。
对于文字识别任务,一般由下面的步骤组成:首先是读取输入的图像,提取图像特征,因此,需要有个卷积层用于读取图像和提取特征;然后,由于文本序列是不定长的,因此需要处理不定长序列预测的问题;再次,为了提升模型的适用性,最好不要要求对输入字符进行分割,直接可进行端到端的训练,这样可减少大量的分割标注工作,这时就要引入 CTC 模型(Connectionist temporal classification, 联接时间分类)来解决样本的分割对齐的问题;最后,根据一定的规则,对模型输出结果进行纠正处理,输出正确结果。
最近流行的技术解决方案中,考虑用一个多目标网络直接训练出一个端到端的模型以替代两阶段模型。在训练阶段,端到端模型的输入是训练图像及图像中的文本坐标、文本内容,模型优化目标是输出端边框坐标预测误差与文本内容预测误差的加权和。在实施阶段,原始图像经过端到端模型处理后直接输出预测文本信息。相比于传统方案,该方案中模型训练效率更高、资源开销更少。

我们在这篇报告中分别总结了OCR中必备的文本检测模型、文字识别模型和端到端的方法。其中,文本检测模型主要考虑复杂场景中的深度学习模型。
一、文本检测模型
1、 EAST
EAST(Efficient and Accuracy Scene Tex)是旷世科技发布在CVPR2017的作品,由于提供了方向信息,EAST可以检测各个方向的文本。EAST的整体网络结构分为3个部分:(1) 特征提取层,使用的基础网络结构是PVANet,分别从stage1、stage2、stage3、stage4抽出特征,即一种FPN(feature pyramid network)的思想;(2) 特征融合层,在抽出的特征层从后向前做上采样,然后执行concat;(3) 输出层,输出一个score map和4个回归的框加上1个角度信息,或者输出一个scoremap和8个坐标信息。
具体的,图1给出原文的网络结构图,该模型可以分解为三个部分:特征提取器stem、特征合并分支和输出层。如图所示,输入一张图片,经过四个阶段的卷积层可以得到四张feature map, 分别为f_4、f_3、f_2、f_1,它们相对于输入图片分别缩小1/4、1/8、1/16、1/32,之后使用上采样、concat(串联)、卷积操作依次得到h_4、h_3、h_2、h_1,在得到这个融合的feature map后,使用大小为通道数为32的卷积核卷积得到最终的feature map。得到最终的feature map后,使用一个大小为1x1通道数为1的卷积核得到一张score map用表示。在feature map上使用一个大小为1x1通道数为4的卷积核得到text boxes,使用一个大小为1x1通道数为1的卷积核得到text rotation angle,这里text boxes和text rotation angle合起来称为geometry map,并用F_g表示。
 图1文本检测模型结构
图1文本检测模型结构
 图2 EAST pipeline
图2 EAST pipeline
图2展示了EAST的pipeline。将一幅图像送入FCN( fully convolutional network),并生成多通道的像素级文本分数图和几何图形。其中一个预测通道是一个分数图,其像素值的范围是[0, 1]。其余的通道表示从每个像素的角度来看包围着这个词的几何形状。分数代表了在同一位置预测的几何形状的置信度。
F_s大小为原图的1/4通道数为1,每个像素表示对应于原图中像素为文字的概率值,所以值在[0,1]范围内。F_g大小也为原图的1/4通道数为5,即4+1(text boxes + text rotation angle)。text boxes通道数为4,其中text boxes每个像素如果对应原图中该像素为文字,四个通道分别表示该像素点到文本框的四条边的距离,范围定义为输入图像大小,如果输入图像为512,那范围就是[0,512]。text rotation angle通道数为1,其中text rotation angle每个像素如果对应原图中该像素为文字,该像素所在框的倾斜角度,角度的度数范围定义为[-45,45]。
损失函数为:





其中,?_s和?_g分别表示score map和geometry map的损失。score map采用交叉熵计算,geometry map用的是IoU loss的计算方式。
最后文章还提出了Locality-Aware NMS,先合并一次窗口,然后采用标准的NMS去抑制窗口。locality_aware_nms在标准nms的基础上加了weighted_merge,将2个IoU高于某个threshold的输出框进行基于得分的合并。合并后的输出框的坐标数值介于2个合并的输入框之间,从而有效利用所有回归出的框的坐标信息,减少位置误差。

| 项目 | SOTA!平台项目详情页 |
| EAST | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/east |
2、 PixelLink
我们上述介绍的文本检测算法中大部分是由文本/非文本分类和位置回归任务组成的,而且回归在获取bounding box中扮演关键的角色。PixelLink放弃了回归的方式去检测bounding box,转而采用实例分割的方式,把文字区域分割出来,然后找到相应的外接矩形。相比于基于回归的方法,PixelLink性能更优,且需要更少的训练数据和迭代次数。
PixelLink网络的backbone采用的是VGG16,并将最后两层全连接层改为卷积层,结构采用的是FCN的结构,文章尝试了两种feature map的融合结构,分别取{conv2_2, conv3_3, conv4_3, conv5_3, fc_7}进行融合和取{conv3_3, conv4_3, conv5_3, fc_7}进行融合。输入为图像,输出为18通道的结果,其中,2通道表示预测的每个像素是否为文本,16通道表示每个像素与它八个邻域是否需要连接的概率图。在得到上述的18个通道后,先是使用了两个阈值分别对像素预测结果和link预测的结果进行过滤,然后对于预测为正样本的像素结合link通道的预测结果将所有像素连接起来,这样就能得到文本检测的区域。大多数文字检测算法的bounding box都是使用regression的方式得到,和回归不同,论文使用了实例分割的方法先得到文字区域,然后使用opencv中的minAreaRect 算法得到相应的矩形(该函数是输出包围点集的最小矩形,该矩形可以是旋转的)。这样就可以输出一些列的文本框了,但是文章为了防止一些噪声的影响,将检查结果中短边小于10或者面积小于300的文本框进行滤除,从而得到最终的文本检查结果。
PixelLink完整的结构如图3。
 图3 PixelLink的架构。训练一个CNN模型来进行两种像素级的预测:文本/非文本预测和Link预测。经过阈值处理后,positive像素被positive Link连接起来,实现实例分割。然后应用minAreaRect直接从分割结果中提取边界框。可以通过后置过滤来有效去除预测的噪声。为了更好地说明问题,作者展示了一个输入样本。虚线框中的八个热图代表了八个方向的Link预测。尽管有些词在文本/非文本预测中难以分离,但通过Link预测,它们是可以分离的
图3 PixelLink的架构。训练一个CNN模型来进行两种像素级的预测:文本/非文本预测和Link预测。经过阈值处理后,positive像素被positive Link连接起来,实现实例分割。然后应用minAreaRect直接从分割结果中提取边界框。可以通过后置过滤来有效去除预测的噪声。为了更好地说明问题,作者展示了一个输入样本。虚线框中的八个热图代表了八个方向的Link预测。尽管有些词在文本/非文本预测中难以分离,但通过Link预测,它们是可以分离的
PixelLink的loss function由每个像素的分类损失函数和link损失函数组成,都采用了交叉熵。由于instance的大小不同,一些图像文字区域的面积大于所有其他文字的面积,因此提出一种实例平衡交叉熵损失函数,即为每一个instance计算一个权重:权重为所有像素面积的平均值除以每一个instance的面积。训练过程中采取了OHEM(Online Hard Example Ming)的训练策略,选取r x S个负样本中loss最高的像素,其中,r为负样本与正样本的比值,一般选取3。link 的loss是要分成正负link分开计算的,分开计算后对正负link loss进行归一化后相加,形成最终的link loss。
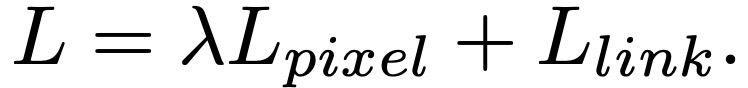



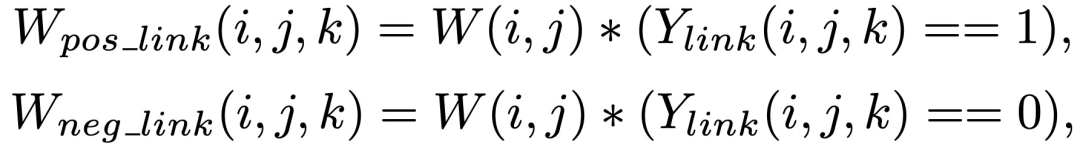
| 项目 | SOTA!平台项目详情页 |
| PixelLink | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/pixellink |
3、TextBoxes++
TextBoxes++主要是受到SSD的default box启发,在SSD框架基础之上做了一些调整,从而能够检测倾斜文本。SSD中default box 是水平的框,不能检测倾斜的文字。为了检测倾斜的文字,TextBoxes++采用四边形或旋转矩形来作为default box回归的target。为了更加密集的覆盖图像中的文字,对default box 做了垂直方向的偏移,更加密集的覆盖图像。同时,为了使感受野更加适应文本行,使用了长条状的卷积核。在训练过程中,使用了OHEM(Online Hard Example Ming)和数据增强,并且数据增强使用了随机裁剪的策略来增强对小目标的检测。TextBoxes++在6个不同的scale下检测旋转文字,在测试过程中,将所有的bounding box汇集到一起并做一起级联的NMS。最后,将CRNN接在后端,利用文字识别的高语义去优化检测过程。
TextBoxes++的backbone是经典的VGG16,保持前五个卷积层(conv1-conv5),并通过参数下采样方法将最后两个全连接转化成卷积层(conv6-conv7),然后在后面再加上8个卷积层,每两个一组(conv8-conv11),形成四个不同分辨率的stage。类似于SSD,不同scale的层都会接入到Multiple output layers,也叫text-box layers。它负责将不同scale下检测到的框进行一个聚合,并做一个级联的NMS。Textboxes++是一个全卷积的结构,因此在训练和测试的过程中可以接受不同大小的图片。不同于Textboxes,TextBoxes++将最后一个global average pooling 替换成了卷积层,这样有益于多尺度的训练和测试。
 图4 TextBoxes++是一个全卷积网络,包括来自VGG-16的13层,然后是10个额外的卷积层,6个文本框层连接到6个中间卷积层。文本框层的每个位置预测每个默认框的n维向量,包括文本存在分数(2维)、水平边界矩形偏移量(4维)和旋转矩形边界框偏移量(5维)或四边形bounding box偏移量(8维)。在测试阶段应用非最大抑制,以合并所有6个文本框层的结果。"#c "代表通道的数量
图4 TextBoxes++是一个全卷积网络,包括来自VGG-16的13层,然后是10个额外的卷积层,6个文本框层连接到6个中间卷积层。文本框层的每个位置预测每个默认框的n维向量,包括文本存在分数(2维)、水平边界矩形偏移量(4维)和旋转矩形边界框偏移量(5维)或四边形bounding box偏移量(8维)。在测试阶段应用非最大抑制,以合并所有6个文本框层的结果。"#c "代表通道的数量
垂直偏移的default box
text-box layer在输入的特征图的基础上同时预测classification和regression,输出的bounding box包括旋转的bounding box和包含对应旋转矩形的最小外接矩形。这个可以通过回归特征图上的每个像素对应的default box 的偏移来实现。在训练过程中,default box通过计算与ground truth的overlap来匹配ground truth,匹配策略和SSD相同。由于ground truth很多时候是倾斜的,因此,在匹配的时候,default box与ground truth的最小外接矩形计算IoU。因为default box 有很多不同的长宽比,这样可以使其更加适应任务。
卷积核形状的选择
对于水平框的情况下卷积核的形状是1 x 5 ,但是对于带有旋转情况下文章选择的是3 x 5。这种inception-style的不规则卷积核可以更好的适应长宽比更大的文字。由于inception结构,这种方形的感受野带来的噪声信号也可以被避免。
训练部分
损失函数采用了和SSD相同的函数,classification采用softmax交叉熵,regression采用smooth L1。

训练过程采用OHEM策略,不同于传统的OHEM,训练分为两个stage,stage1的正负样本比为1:3,stage2的正负样本比为1:6。
数据增强策略就是在原图随机裁剪一块与ground truth 的Jaccard overlap大于最小值的图片,此外增加一个目标收敛的约束。对于裁剪后的bounding box B和ground-truth bounding box G,Jaccard overlap J和物体覆盖度C定义为:
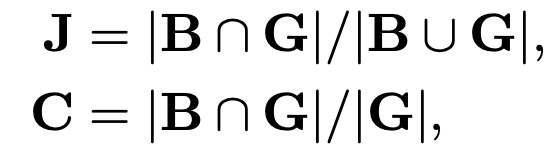
其中,| · |表示cardinality(即面积)。基于物体覆盖率C的随机裁剪策略更适合于小物体,如自然图像中的大多数文字。
级联NMS
由于计算倾斜文字的IoU较为耗时,作者在中间做了一个过渡,先计算所有框的最小外接矩形的IoU,做一次阈值为0.5的NMS,消除一部分框,然后在计算倾斜框的IoU的基础上做一次阈值为0.2的NMS。
端到端文字识别
最后,在Textboxes++后端接上CRNN(Convolutional Recurrent Neural Network)的框架,可以识别出相应的文字,然后通过文字的语义信息优化检测框的位置。整个CRNN网络结构包含三部分,从下到上依次为:CNN(卷积层),使用深度CNN,对输入图像提取特征,得到特征图;RNN(循环层),使用双向RNN(BLSTM)对特征序列进行预测,对序列中的每个特征向量进行学习,并输出预测标签(真实值)分布;CTC loss(转录层),使用 CTC 损失,把从循环层获取的一系列标签分布转换成最终的标签序列。关于CRNN我们会在后文“文字识别模型”章节中详细介绍。
| 项目 | SOTA!平台项目详情页 |
TextBoxes++ |
前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/textboxes-_1 |
