
1 卷积神经网络简介
卷积神经网络是一类包含卷积计算并且具有深度结构的前馈神经网络,是深度学习的重要算法之一。卷积神经网络通过有效提取图像的平移不变特征,CNN在计算机视觉等领域得到了广泛的应用。
此次推文主要讲解经典的卷积神经网络,包括,LeNet、AlexNet、VGGNet、GoogleNet、ResNet、DenseNet、SENet、SKNet以及ResNeStNet,后续会讲解轻量化模型和循环神经网络。
1.1、LeNet
1988年,Yann LeCun提出了用于手写字符识别的卷积网络模型LeNet5。其原理结构比较清晰,很多企业都采用了该模型用于识别现实场景中的数字,在邮政编码、手写数字识别方面都能够达到商用的程度,可见LeNet在AI领域的开创性地位。
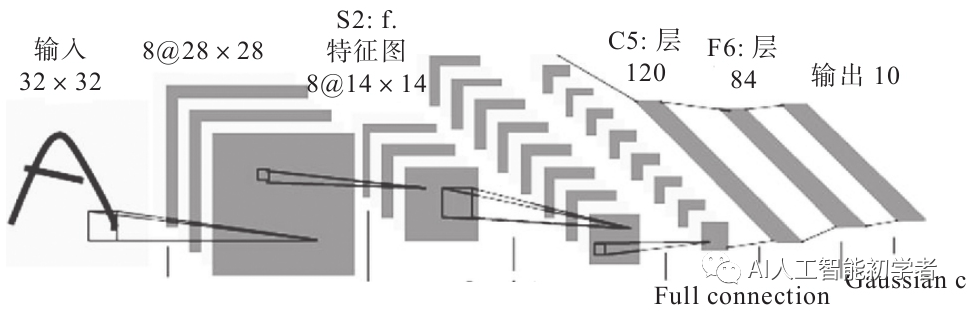
LeNet虽然是一个很小的模型,但是麻雀虽小五脏俱全,以下是LeNet的PyTorch实现:
class LeNet(nn.Module): def __init__(self): super(LeNet, self).__init__() # 输入的通道是1(黑白单通道),输出的通道是6, kernel大小为5 # 卷积层1 输入尺寸 (32, 32),输出大小 (28, 28) self.conv1 = nn.Conv2d(1, 6, 5) #输入的通道是6,输出的通道是16,kernel的大小是5 # 卷积层2 输入尺寸(14, 14),输出大小 (10, 10) self.conv2 = nn.Conv2d(6, 16, 5) # 输入的维度是16*5*5,输出的维度是120 #全连接层1 self.fc1 = nn.Linear(16 * 5 * 5, 120) # 全连接层2 self.fc2 = nn.Linear(120, 84) # 全连接层3 self.fc3 = nn.Linear(84, 10) def forward(self, x): # 推理过程 # 输入大小为(28,28),输出大小为(14,14) x = F.max_pool2d(F.relu(self.conv1(x)), 2) # max pooling x = F.max_pool2d(F.relu(self.conv2(x)), 2) #拉直 x = x.view(x.shape[0], -1) #全卷积之后输入激活函数 x = F.relu(self.fc1(x)) # 全卷积之后输入激活函数 x = F.relu(self.fc2(x)) # 压缩到类别数目 x = self.fc3(x) return x
1.2 AlexNet
AlexNet是2012年提出的,AlexNet直接将ImageNet数据集的识别错误率从之前的非深度学习方法的28.2%降低到16.4%。AlexNet算是这波AI热潮的引爆点。AlexNet的结构与LeNet非常相似,但是做了很多改进,具体如下。
- 更深的网络,增强了模型的表示能力。
- 成功添加了ReLU激活函数作为CNN的激活层,缓解了sigmoid激活函数的梯度消失问题,收敛也更快。
- 提出了局部响应归一化(Local Response Normalization,LRN),对局部神经元创建竞争机制,抑制反馈较少的神经元,增强模型的泛化能力。
- 设计并使用了Dropout以随机忽略部分神经元,从而避免出现模型过拟合的问题。
- 添加了裁剪、旋转等方式增强数据。

以下是基于PyTorch实现的AlexNet模型:
import torch.nn as nn class AlexNet(nn.Module): def __init__(self, num_classes=1000): super(AlexNet, self).__init__() self.features = nn.Sequential( nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(64, 192, kernel_size=5, padding=2), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(192, 384, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), ) self.classifier = nn.Sequential( nn.Dropout(), nn.Linear(256 * 6 * 6, 4096), nn.ReLU(inplace=True), nn.Dropout(), nn.Linear(4096, 4096), nn.ReLU(inplace=True), nn.Linear(4096, num_classes), ) def forward(self, x): x = self.features(x) x = x.view(x.size(0), 256 * 6 * 6) x = self.classifier(x) return x
1.3 VGGNet
VGGNet在2014年的ImageNet比赛中,证明了增加网络的深度能够在一定程度上提升网络的最终性能。VGG有两种结构,分别是VGG16和VGG19,二者之间没有本质的区别,只是网络深度不同。
相较于AlexNet,VGGNet的主要改进是采用连续的3×3卷积核代替AlexNet中比较大的卷积核:11×11、7×7、5×5。对于给定的感受野,采用堆积的小卷积核优于采用大的卷积核,主要原因是能在不降低性能的前提下,极大地降低参数量。
展开来看,VGG使用三个3×3卷积核来替代一个7×7卷积核,使用两个3×3卷积核来替代一个5×5卷积核,这样可以在保证相同感受野的前提下,降低参数量,使得增加网络的深度成为可能(显存有限的条件下),从而极大地提升了网络的性能。原理如图所示:


以下是基于PyTorch实现的AlexNet模型:
class Vgg16(torch.nn.Module): def __init__(self): super(Vgg16, self).__init__() self.conv1_1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1) self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1) self.conv2_1 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1) self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1) self.conv3_1 = nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1) self.conv3_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1) self.conv3_3 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1) self.conv4_1 = nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1) self.conv4_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1) self.conv4_3 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1) self.conv5_1 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1) self.conv5_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1) self.conv5_3 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1) def forward(self, X): h = F.relu(self.conv1_1(X)) h = F.relu(self.conv1_2(h)) relu1_2 = h h = F.max_pool2d(h, kernel_size=2, stride=2) h = F.relu(self.conv2_1(h)) h = F.relu(self.conv2_2(h)) relu2_2 = h h = F.max_pool2d(h, kernel_size=2, stride=2) h = F.relu(self.conv3_1(h)) h = F.relu(self.conv3_2(h)) h = F.relu(self.conv3_3(h)) relu3_3 = h h = F.max_pool2d(h, kernel_size=2, stride=2) h = F.relu(self.conv4_1(h)) h = F.relu(self.conv4_2(h)) h = F.relu(self.conv4_3(h)) relu4_3 = h return [relu1_2, relu2_2, relu3_3, relu4_3]
1.4 GoogLeNet
VGG、AlexNet的绝大部分参数集中在最后几个全连接(FC)层,然而FC组件不仅参数多,而且容易过拟合,之后便有了NIN。NIN使用1×1卷积核创造性地解决了这个问题,极大地降低了参数量,同时还提升了效果。
受到NIN的启发,Google的研究小组提出了Inception模块一种高效表达特征的稀疏性结构,主要是增加对尺度的适应性,达到提升特征表达能力的效果。Inception的结构如图所示:


因为5×5的卷积核可能会导致参数量过大,所以需要通过降维控制参数量。GoogLeNet的另外一个贡献是将最后的卷积层都替换为全局均值池化层,因为Pooling的操作没有参数,因此能够进一步减少网络的参数量(这里笔者认为池化并不是一个很好的发明,如果能够避免尽可能少地使用该操作),便于应用于更大更深的网络,同时使准确率提升至93.3%(ImageNet上的top-5),速度还比VGG快很多。以下是基于PyTorch实现的GoogLeNet模型:
class Inception(nn.Module): def __init__(self, in_planes, n1x1, n3x3red, n3x3, n5x5red, n5x5, pool_planes): super(Inception, self).__init__() # 1x1 卷积 self.conv1 = nn.Sequential(nn.Conv2d(in_planes, n1x1, kernel_size=1), nn.BatchNorm2d(n1x1),nn.ReLU(True)) # 1x1卷积 + 3x3卷积 self.conv2 = nn.Sequential(nn.Conv2d(in_planes, n3x3red, kernel_size=1), nn.BatchNorm2d(n3x3red),nn.ReLU(True), nn.Conv2d(n3x3red, n3x3, kernel_size=3, padding=1), nn.BatchNorm2d(n3x3),nn.ReLU(True)) # 1x1卷积 + 5x5卷积 self.conv3 = nn.Sequential(nn.Conv2d(in_planes, n5x5red, kernel_size=1), nn.BatchNorm2d(n5x5red),nn.ReLU(True), nn.Conv2d(n5x5red, n5x5, kernel_size=3, padding=1), nn.BatchNorm2d(n5x5),nn.ReLU(True), nn.Conv2d(n5x5, n5x5, kernel_size=3, padding=1), nn.BatchNorm2d(n5x5),nn.ReLU(True)) # 3x3卷积 + 1x1卷积 self.conv4 = nn.Sequential(nn.MaxPool2d(3, stride=1, padding=1), nn.Conv2d(in_planes, pool_planes, kernel_size=1), nn.BatchNorm2d(pool_planes),nn.ReLU(True)) def forward(self, x): out1 = self.conv1(x) out2 = self.conv2(x) out3 = self.conv3(x) out4 = self.conv4(x) return torch.cat([out1, out2, out3, out4], 1) # GoogleNet class GoogleNet(nn.Module): def __init__(self, out_dim): super(GoogleNet, self).__init__() self.pre_layer = nn.Sequential(nn.Conv2d(3, 192, kernel_size=3, padding=1), nn.BatchNorm2d(192), nn.ReLU(True) ) self.a3 = Inception(192, 64, 96, 128, 16, 32, 32) self.b3 = Inception(256, 128, 128, 192, 32, 96, 64) self.maxpool = nn.MaxPool2d(3, stride=2, padding=1) self.a4 = Inception(480, 192, 96, 208, 16, 48, 64) self.b4 = Inception(512, 160, 112, 224, 24, 64, 64) self.c4 = Inception(512, 128, 128, 256, 24, 64, 64) self.d4 = Inception(512, 112, 144, 288, 32, 64, 64) self.e4 = Inception(528, 256, 160, 320, 32, 128, 128) self.a5 = Inception(832, 256, 160, 320, 32, 128, 128) self.b5 = Inception(832, 384, 192, 384, 48, 128, 128) self.avgpool = nn.AvgPool2d(8, stride=1) self.linear = nn.Linear(1024, out_dim) def forward(self, x): x = self.pre_layer(x) x = self.a3(x) x = self.b3(x) x = self.maxpool(x) x = self.a4(x) x = self.b4(x) x = self.c4(x) x = self.d4(x) x = self.e4(x) x = self.maxpool(x) x = self.a5(x) x = self.b5(x) x = self.avgpool(x) x = x.view(x.size(0), -1) x = self.linear(x) return x
