导言
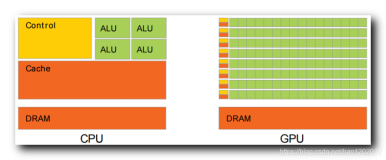
XGBoost是一种强大的机器学习算法,但在处理大规模数据时,传统的CPU计算可能会变得缓慢。为了提高性能,XGBoost可以利用GPU进行加速。本教程将介绍如何在Python中使用XGBoost进行GPU加速以及性能优化的方法,并提供相应的代码示例。
安装 GPU 支持
首先,您需要确保您的系统上安装了支持 GPU 的 XGBoost 版本。您可以通过以下命令安装 GPU 版本的 XGBoost:
pip install xgboost-gpu
如果您的系统中没有安装CUDA,您还需要安装CUDA Toolkit。请参考CUDA Toolkit的官方文档进行安装:CUDA Toolkit
启用 GPU 加速
在使用 GPU 加速之前,您需要设置 XGBoost 来利用 GPU。以下是一个简单的示例:
import xgboost as xgb
# 启用 GPU 加速
params = {
'tree_method': 'gpu_hist', # 使用 GPU 加速
'predictor': 'gpu_predictor' # 使用 GPU 进行预测
}
# 创建 GPU 加速的 XGBoost 模型
gpu_model = xgb.XGBRegressor(**params)
性能优化
除了使用 GPU 加速外,还可以通过调整其他参数来优化 XGBoost 的性能。以下是一些常用的性能优化参数:
n_estimators:增加弱学习器的数量可能会提高性能,但会增加训练时间。
max_depth:限制树的最大深度可以降低过拟合风险并提高性能。
learning_rate:减小学习率可能会提高模型的泛化能力,但会增加训练时间。
subsample:减小子样本比例可以降低过拟合风险并提高性能。
colsample_bytree:限制每棵树使用的特征数量可以降低过拟合风险并提高性能。
代码示例
以下是一个使用 GPU 加速和性能优化的示例:
import xgboost as xgb
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 加载数据集
boston = load_boston()
X, y = boston.data, boston.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 启用 GPU 加速和性能优化
params = {
'tree_method': 'gpu_hist',
'predictor': 'gpu_predictor',
'n_estimators': 1000,
'max_depth': 5,
'learning_rate': 0.1,
'subsample': 0.8,
'colsample_bytree': 0.8
}
# 创建 GPU 加速的 XGBoost 模型
gpu_model = xgb.XGBRegressor(**params)
# 训练模型
gpu_model.fit(X_train, y_train)
# 在测试集上评估模型
y_pred = gpu_model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
结论
通过本教程,您学习了如何在Python中使用XGBoost进行GPU加速以及性能优化的方法。首先,我们安装了支持GPU的XGBoost版本,并启用了GPU加速。然后,我们调整了模型参数以优化性能,并进行了性能评估。
通过这篇博客教程,您可以详细了解如何在Python中使用XGBoost进行GPU加速以及性能优化的方法。您可以根据需要对代码进行修改和扩展,以满足特定性能要求的需求。