
高性能、可商用,国产大模型又有开源新动向。
8 月 7 日,百亿参数高性能通用大模型「XVERSE-13B」宣布开源。

- Hugging Face:https://huggingface.co/xverse/XVERSE-13B
- Github:https://github.com/xverse-ai/XVERSE-13B
而 XVERSE-13B 的打造者,正是前腾讯公司副总裁姚星老师于2021年初创立的AI 与元宇宙技术服务公司元象 XVERSE。

姚星
在离职创业之前,姚星主导创建了腾讯首个人工智能实验室 AI Lab(2016 年)和首个机器人实验室 Robotics X (2018 年),曾推进腾讯在机器学习、计算机视觉、语音到自然语言处理等前沿 AI 技术的研究与应用,主导推出多个有行业影响力的应用与产品,包括国家围棋队 AI 陪练「绝艺」、王者荣耀 AI「绝悟」、中国首款临床用智能显微镜、AI 驱动的新药发现平台「云深智药」及腾讯智慧种植方案 iGrow 等。
打造最强性能的开源大模型
XVERSE-13B 是目前同尺寸中效果最好的多语言大模型,可免费商用。它具备了高性能、全开源、可商用等诸多优势,能大大降低高校和企业部署使用大模型的成本,不仅实现了国产可替代,也是中文应用更好的选择。
在多项权威的标准中文和英文测评中,性能超越了 Llama-2-13B、Baichuan-13B 等国内外开源大模型(见下图一)。
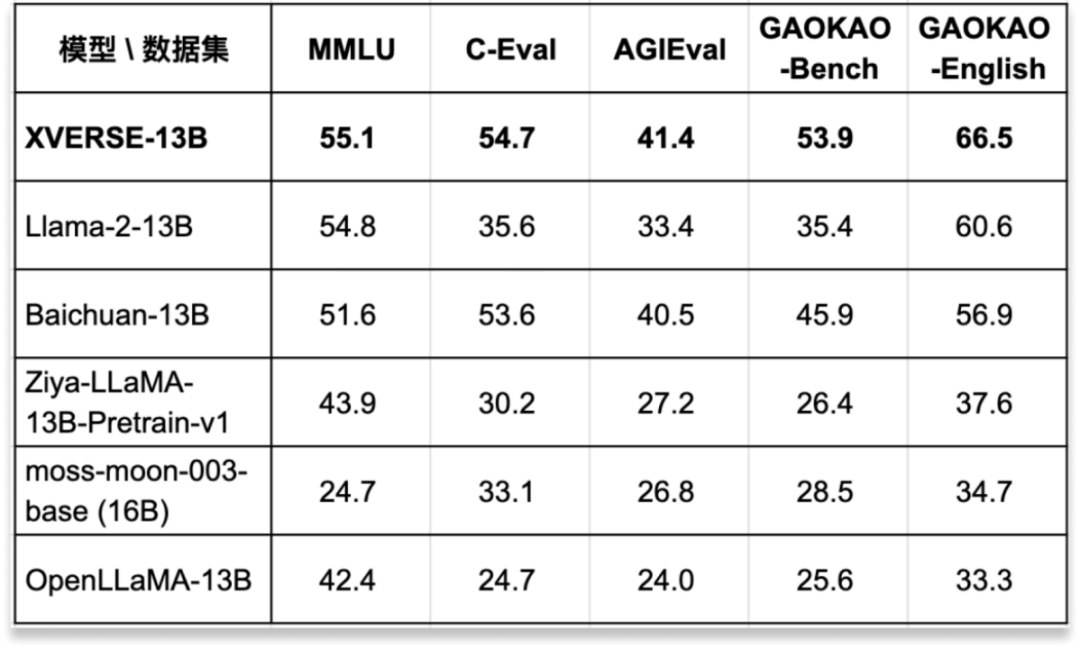
图一:经过多项权威测评,XVERSE-13B 是目前同尺寸中效果最好的多语言大模型。
作为一个通用大模型,XVERSE-13B 可提供文本生成、自动化写作、数据分析、知识问答、多语言翻译、个性化交互、人物角色扮演、专业小助手等多方面的生成服务,在医疗、文旅、金融和娱乐等多个行业具有广阔应用前景。
据了解,元象近期还将发布大模型 Chat 版,开箱即用,持续优化开发者体验。
训练语料对大模型效果至关重要。XVERSE-13B 构建了一个高达 1.4 万亿高质量、多样化 tokens 的训练数据集,同时优化采样策略和数据组织方式,让模型支持中、英、俄、西等 40 多种语言,并且多语言任务处理的性能与效果俱佳。
XVERSE-13B 支持 8192 的上下文窗口,是同尺寸模型中最长的,从而能出色应对复杂场景,比如更长的多轮对话、知识问答与摘要等,应用范围更广泛。
模型使用标准 Transformer 网络结构,从零开始训练,还自主研发多项关键技术,包括高效算子、显存优化、并行调度策略、数据 - 计算 - 通信重叠、平台和框架协同等,让训练效率更高,模型稳定性强,在千卡集群上的峰值算力利用率可达到 58.5%,位居业界前列。
多个权威中文测评中表现优异,超越 Baichuan-13B
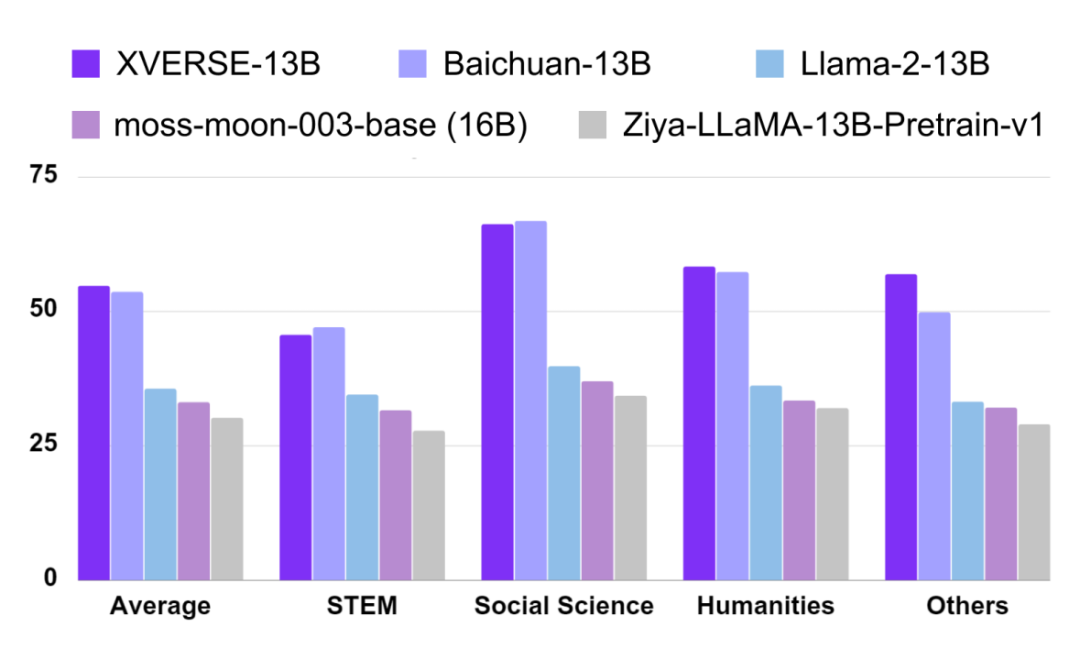
为验证模型各项能力,XVERSE-13B 通过 C-Eval、AGIEval 和 GAOKAO-Bench 等三个最具影响力的中文测评基准的综合评估(图二),表现优异,超越了同参数规模主流模型,如 Baichuan-13B、Llama-2-13B、Ziya-LLaMA-13B 等。

图二:在多个权威中文测评中,XVERSE-13B 表现超越了同参数规模的主流模型。
在中文 C-Eval 的测评中(图三),XVERSE-13B 综合评分达到了 54.7 分,超越了同参数规模的主流模型。C-EVAL 测评基准由上海交通大学、清华大学以及爱丁堡大学联合创建,是面向中文语言模型的综合考试测试集,覆盖了 52 个来自不同行业领域的学科。
图三:C-Eval 中文测评结果。
在 AGIEval 测评里,XVERSE-13B 综合评分达到 41.4 分,超越了同参数规模主流模型(图二)。AGIEval 测评基准由微软研究院发起,旨在全面评估基础模型在人类认知和问题解决相关任务上的能力,包含了中国的高考、司法考试,以及美国的 SAT、LSAT、GRE 和 GMAT 等 20 个公开且严谨的官方入学和职业资格考试。
在 GAOKAO-Bench 测评中,XVERSE-13B 综合评分达到了 53.9 分,显著领先于同参数规模的主流模型(图二)。GAOKAO-Bench 测评基准是复旦大学研究团队创建的测评框架,以中国高考题目作为数据集,用于测评大模型在中文语言理解和逻辑推理能力方面的表现。
英文测评表现领先 Llama-2-13B
XVERSE-13B 的英文表现同样出色,在英文最权威评测 MMLU 中,其综合评分高达 55.1 分,几乎在所有维度超越了同参数规模的主流模型(图四),包括 Llama-2-13B、Baichuan-13B 等。
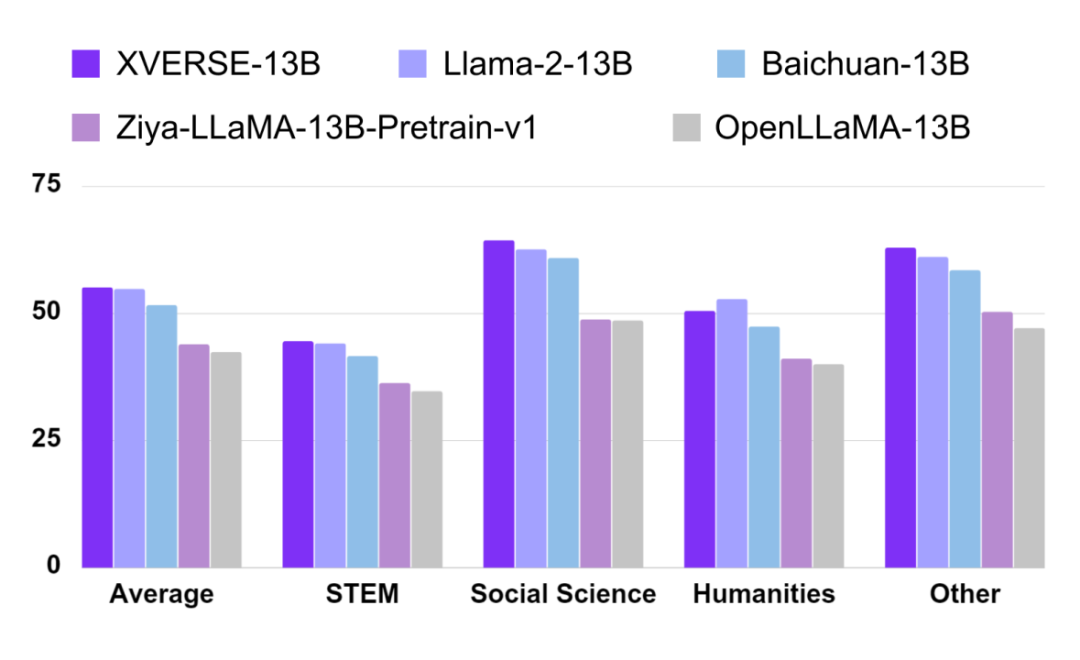
图四:MMLU 英文测评结果。
MMLU 由加州大学伯克利分校等知名高校共同打造,集合了科学、工程、数学、人文、社会科学等领域的 57 个科目,主要目标是对模型的英文跨学科专业能力进行深入测评。其内容广泛,从初级水平一直涵盖到高级专业水平。
需要强调的是,测评只反映了大模型底座的核心能力,元象将持续迭代优化,全面提升模型能力。
免费可商用 哈工大率先使用助力研究
秉持开源精神,XVERSE-13B 代码采用 Apache-2.0 协议,向学术研究完全开源,企业只需简单登记,即可免费商用。
哈尔滨工业大学(下称「哈工大」)作为我国最早从事自然语言处理研究的顶级科研团队,已经率先使用 XVERSE-13B 大模型推进相关研究工作。哈工大计算机科学与技术学院张伟男教授表示,「开源是互联网时代主流模式,不仅能贡献社区,推动技术持续创新,还能利用协同解决算法透明性、稳定性、公众信任度等共性问题。」
元象 XVERSE 创始人姚星表示:「真实世界的感知智能(3D),与真实世界的认知智能(AI),是探索通用人工智能(AGI)的必由之路,也是元象持续探索 3D 与 AI 前沿技术的动力。XVERSE-13B 是我们在国产技术自立自强上迈出的一小步,而开源开放将激发大模型生态活力,让 AI 的未来发展迈出一大步,为实体经济、数字经济的发展注入强劲动力。我们期待与众多企业与开发者携手,开创大模型商用新纪元。」




