
梯度积累与微批
梯度累积是一种在训练过程中虚拟增加批大小的方法,当可用的 GPU 内存不足以容纳所需的批量大小时,这是非常有用的。并且这种方法只会在运行时产生影响,建模性能并不会受到影响。
梯度累积中,每批计算的量较小,并在多次迭代中累积梯度(通常求和或求平均),而不是在每个批次之后立刻更新模型权重。一旦累积的梯度达到目标「虚拟」批大小,模型权重就会用累积的梯度更新。
为了实现梯度积累,只需要对向前和向后传球进行两次小的修改:
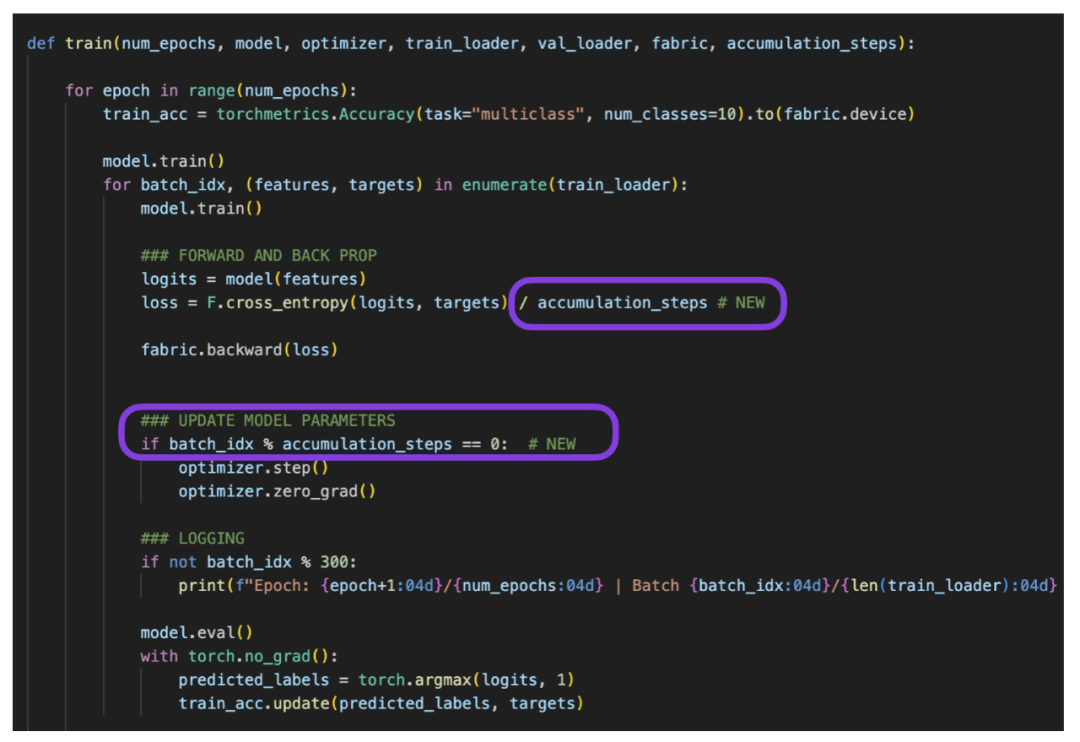
05_gradient-acum.py 中的代码修改
本文作者的另一篇文章《使用梯度累积在单个 GPU 上微调 LLM》,更详细地介绍了梯度累积的细节。
文章地址:https://lightning.ai/blog/gradient-accumulation/
有效批大小为 16,并且累积步数为 4,意味着实际批大小为 4(因为 16/4=4)。

05_gradient-acum.py 的结果
这种技术的缺点是运行时间从 3.96 分钟增加到 12.91 分钟。
值得注意的是,批大小最小可以减少到 1,进一步减少 75% 的内存消耗。
使用更精简的优化器
时下流行的 Adam 优化器其实附带了额外的参数,例如,Adam 为每个模型参数提供了 2 个额外的优化器参数(平均值和方差)。
因此,通过将 Adam 与 SGD 等无状态优化器进行交换,可以将参数数量减少 2/3,这在使用 ViT 和 LLM 时非常重要。
普通 SGD 的缺点是收敛性较差。因此,Adam 与 SGD 交换后,需要引入余弦衰减学习速率调度器来进行补偿。
简而言之,通过将以下代码
optimizer = torch.optim.Adam(model.parameters(), lr=5e-5)
替换为
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) num_steps = NUM_EPOCHS * len(train_loader)scheduler = torch.optim.lr_scheduler.CosineAnnealingLR( optimizer, T_max=num_steps)
通过这种变化,模型能够在保持大约 97% 分类准确率的同时减少峰值内存消耗:

06_sgd-with-scheduler.py 的结果
在目标设备上创建模型
在 PyTorch 中实例化模型时,通常是首先在 CPU 设备上创建它,然后将它转移到目标设备上,并将其转换为所需的精度:
model = vit_l_16(weights=ViT_L_16_Weights.IMAGENET1K_V1)model.cuda().float16()
但是 CPU 上生成完整精度的中间模型,是一种低效的方法。所以,可以使用 Fabric 中的 init_module 上下文在目标设备(例如 GPU)上直接创建所需精度的模型:
import lightning as L fabric = Fabric(accelerator="cuda", devices=1, precision="16-true") with fabric.init_module(): model = vit_l_16(weights=ViT_L_16_Weights.IMAGENET1K_V1)
在这种特定情况下(模型),前向通过期间的峰值内存大于其全精度表示中的大小。对模型加载本身对 fabric.init_module 方法进行基准测试,结果如下:
- 没有 init_module 的 GPU 峰值内存:1.24 GB(07_01_init-module.py)
- GPU 带 init_module 的峰值内存:0.65 GB(07_03_init-module.py)
可以看到,在这种情况下,init_module 将模型加载的峰值内存需求减少了 50%。
有关 init_module 的更多详细信息,可以参阅这篇关于大型模型的高效初始化的的文章。
文章地址:https://lightning.ai/pages/community/efficient-initialization-of-large-models/
分布式训练与张量共享
下一个修改是多 GPU 训练。多个 GPU 可供使用是有效的,因为这样做可以更快地训练模型。
然而,本文探讨的是内存节省。因此,需要一种更先进的分布式多 GPU 策略,称为完全共享数据并行(FSDP),该策略利用数据并行性和张量并行性在多个设备上共享大权重矩阵。
但是如果模型已经很小了,例如将此技术添加到上面第 7 节的代码中时,是几乎看不到任何效果的。因此,为了纯粹地关注分片的效果,可以与第 1 节中的全精度基线进行比较。
将以下代码
fabric = Fabric(accelerator="cuda", devices=1)
替换为
auto_wrap_policy = partial( transformer_auto_wrap_policy, transformer_layer_cls={EncoderBlock}) strategy = FSDPStrategy( auto_wrap_policy=auto_wrap_policy, activation_checkpointing=EncoderBlock) fabric = Fabric(accelerator="cuda", devices=4, strategy=strategy)

08_fsdp 与 - 01-2.py 的结果
除了手动定义,请也可以使用以下方法,自动确定要分割哪些层:
fabric = Fabric(accelerator="cuda", devices=4, strategy="fsdp")
理解数据并行性和张量并行性
在数据并行中,mini-batch 需要继续被划分,并且每个 GPU 上都有一份模型副本。由于多个 GPU 并行工作,能够加快模型训练。

以下是工作原理:
- 在所有 GPU 中复制相同的模型。
- 然后,每个 GPU 被馈送输入数据的不同子集(不同的小批量)。
- 所有 GPU 独立地执行模型的前向和后向传递,计算各自的局部梯度。
- 然后,收集梯度并对所有 GPU 进行平均。
- 然后使用平均梯度来更新模型的参数。
这种方法的主要优点是速度块。由于每个 GPU 都在与其他 GPU 同时处理一个独特的小批量数据,因此可以在更短的时间内在更多数据上训练模型。这可以显著减少训练模型所需的时间,尤其是在使用大型数据集时。
然而,数据并行性有一些局限性。每个 GPU 必须具有模型及其参数的完整副本。这限制了可训练模型的大小,因为模型必须适合单个 GPU 的内存 —— 这对于现代 ViT 或 LLM 来说是不可行的。
与数据并行不同,张量并行将模型本身划分为 GPU。在数据并行中,每个 GPU 都需要适应整个模型,这在训练更大的模型时可能会成为一个限制。然而,张量并行性允许通过分解模型并将其分布在多个设备上来训练对于单个 GPU 来说可能太大的模型。

具体来说,其原理和矩阵乘法相似。按行或按列都可以对模型进行拆解。简单起见,以按列拆解为例,可以将一个大型矩阵乘法运算分解为单独的计算,每个计算都可以在不同的 GPU 上执行,如下图所示。然后将结果连接起来以获得原始结果,从而有效地分配了计算负载。

参数卸载
除了上一节中解释的 FSDP 策略之外,还可以将优化器参数卸载到 CPU,可以通过将以下代码
strategy = FSDPStrategy( auto_wrap_policy=auto_wrap_policy, activation_checkpointing=EncoderBlock,)
替换为
strategy = FSDPStrategy( auto_wrap_policy=auto_wrap_policy, activation_checkpointing=EncoderBlock, cpu_offload=True)
内存消耗从 6.59 GB 减少到 6.03 GB:

09_fsdp-cpu-offload-with-01-2.py 的结果。
美中不足的小缺点是运行时间从 5.5 分钟增加到了 8.3 分钟。
将前面几招连着打出,就成为了最强的降龙十八掌最后一掌!
前几节对优化 ViT 进行了大量介绍,其实这些技术也同样适用于 LLM。
作者在 Lit LLaMA 和 Lit GPT 存储库中使用了许多这些技巧,这些存储库支持 LLaMA、Falcon、Pythia 和其他流行的模型。尽管如此,为了创建一个更通用的例子,作者从流行的 HF transformers 库中微调 LLM,用于对 IMDb 电影评论的情绪进行分类。
使用上述技术,仅使用 1.15 Gb 内存(bonus_DistilBERT-after.py)而不是 3.99 Gb(bonus_bigbird-before.py)就可以训练 DistilBERT 分类器。更令人印象深刻的是,通过将这些技术应用于 transformers 库中的 BigBird 模型,BigBird 仅消耗 4.03 GB(bonus_BigBird-after.py)。
strategy = FSDPStrategy( cpu_offload=True ) fabric = Fabric( accelerator="cuda", devices=4, strategy=strategy, precision="bf16-true" ) with fabric.init_module(): model = AutoModelForSequenceClassification.from_pretrained( "google/bigbird-roberta-base", num_labels=2)
结论
本文展示了 9 种减少 PyTorch 模型内存消耗的技术。当将这些技术应用于 ViT 时,单个 GPU 上减少了 20 倍的内存消耗。可以看到,跨 GPU 的张量分片甚至可以降低内存消耗。同样的优化还使 BigBird LLM 能够仅使用 4GB 峰值 GPU RAM 进行训练。
这些技术都不是特定于模型的,可以与任何 PyTorch 训练脚本一起使用。使用开源 Fabric 库,大多数优化都可以通过一行代码实现。
参考链接:https://lightning.ai/pages/community/tutorial/pytorch-memory-vit-llm/
