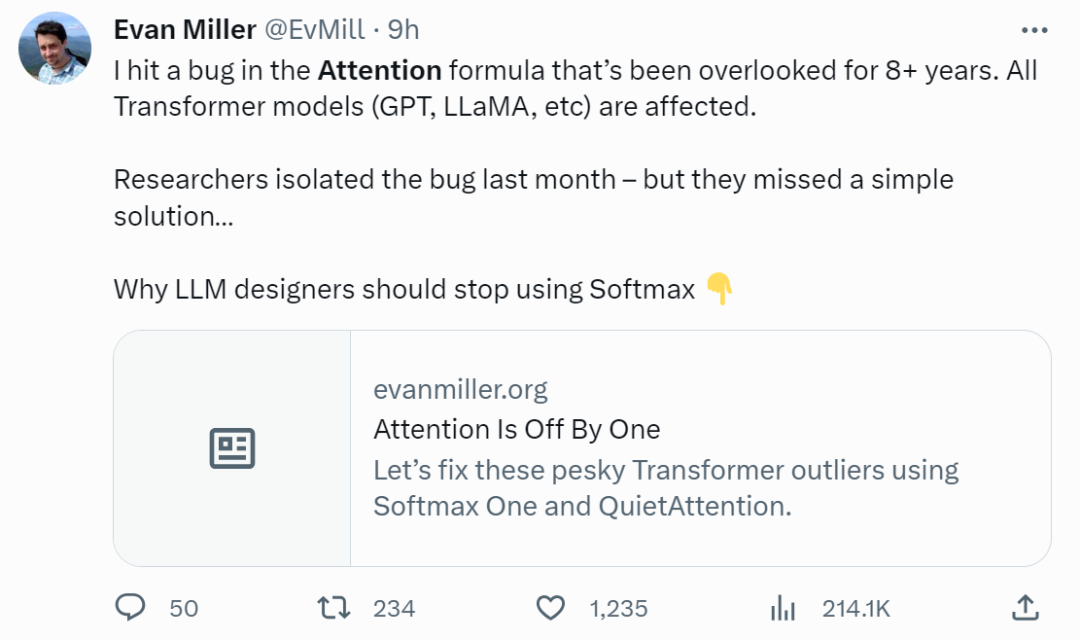
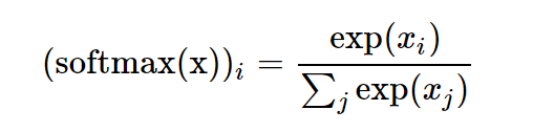「大模型开发者,你们错了。」
「我发现注意力公式里有个 bug,八年了都没有人发现。所有 Transformer 模型包括 GPT、LLaMA 都受到了影响。」
昨天,一位名叫 Evan Miller 的统计工程师的话在 AI 领域掀起了轩然大波。
我们知道,机器学习中注意力公式是这样的:

自 2017 年 Transformer 问世,这个公式已被广泛使用,但现在,Evan Miller 发现这个公式是错的,有 bug!
Evan Miller 的这篇博客解释了当前流行的 AI 模型如何在关键位置出现错误,并使得所有 Transformer 模型都难以压缩和部署。
总结而言,Evan Miller 引入了一种新函数 Quiet Attention,也叫 Softmax_1,这是对传统 softmax 函数的创新调整。

有网友对该博客总结出了一个「太长不看版」。博客作者建议在注意力机制使用的 softmax 公式分母上加 1(不是最终输出 softmax)。注意力单元中的 softmax 使其可以将键 / 查询匹配作为概率;这些概率支持一个键 - 值查找的连续值版本(我们得到的权重不是一个查找的 1/0 输出,而是高权重 = 所需的键 - 值查找)。
分母上加 1 将改变注意力单元,不再使用真实的权重概率向量,而是使用加起来小于 1 的权重。其动机是该网络可以学习提供高权重,这样调整后的 softmax 非常接近概率向量。同时有一个新的选项来提供 all-low 权重(它们提供 all-low 输出权重),这意味着它可以选择不对任何事情具有高置信度。

有人甚至猜测「这就是微软 RetNet 比 transformer 性能更优的原因?」

还有网友表示,这项研究可以促进 LLM 的改进,从而极大对权重进行压缩,使得较小的模型媲美较大的模型:

Miller 表示:你可以像使用传统的 softmax 函数一样使用 Softmax_1 函数,示例如下。
import torchfrom softmax_one.softmax_one import softmax_onex = torch.randn(5)y = softmax_one(x, dim=0)