
时隔 8 个月,谷歌又提出了一种能在 20 秒内实现人脸个性化处理的新生成模型。
此前,谷歌和波士顿大学的研究者提出了一种「个性化(Personalization)」的文本到图像扩散模型 DreamBooth,用户只需提供 3~5 个样本 + 一句话,AI 就能定制照片级图像。
对于「个性化」我们可以这样理解,以输入图像为参考,生成的图像在各种情境和不同风格中都能保持对其身份的高度忠实。
举例来讲,输入左侧 4 张小狗的照片,DreamBooth 就可以生成不同类型的小狗,如小狗在景点里旅游、在海里游泳、趴在窝棚里睡觉、甚至人类给它修剪毛发,而生成的图片都高度保持了原图像的特点。

然而,个性化过程在时间和内存需求方面还存在很多挑战。具体到单个个性化模型,进行微调需要大量的 GPU 时间投入,不仅如此,个性化模型还需要很高的存储容量。
为了克服这些挑战,时隔 8 个月,谷歌又提出了一种新的生成模型 HyperDreamBooth。HyperDreamBooth 可以生成不同上下文和风格的人脸,同时还能保留脸部关键知识。
在只使用一张参考图像的情况下,HyperDreamBooth 在大约 20 秒内实现了对人脸的个性化处理,比 DreamBooth 快 25 倍,比 Textual Inversion 快 125 倍,不仅如此,生成的图像与 DreamBooth 质量一样、风格还多样性。此外,HyperDreamBooth 还比常规的 DreamBooth 模型小 10000 倍。

论文地址:https://arxiv.org/pdf/2307.06949.pdf论文主页:https://hyperdreambooth.github.io/
在我们深入探讨技术细节之前,先看一些效果。
下图中,左边一栏是输入图像,给定一张图像就可以;中间一栏是根据不同的提示生成的人脸,提示语分别是 Instagram 上一张 V 型脸的自拍照;皮克斯卡通人物的 V 型脸;摇滚明星 V 型脸;树皮一样的 V 型脸。最右边生成的是人物专业照片 V 型脸。结果显示,HyperDreamBooth 具有相当大的可编辑性,同时还能保持人物关键面部特征的完整性。

HyperDreamBooth 与 Textual Inversion 、DreamBooth 方法比较有何优势呢?
下图展示了两个示例、5 种风格,结果显示,HyperDreamBooth 可以很好的保持输入图像特性,还具有很强的可编辑性。

接下来我们看看 HyperDreamBooth 具体是如何实现的。
方法介绍
该研究提出的方法由 3 个核心部分组成,分别是轻量级 DreamBooth(Lightweight DreamBooth,LiDB)、预测 LiDB 权重的 HyperNetwork 和 rank-relaxed 快速微调。
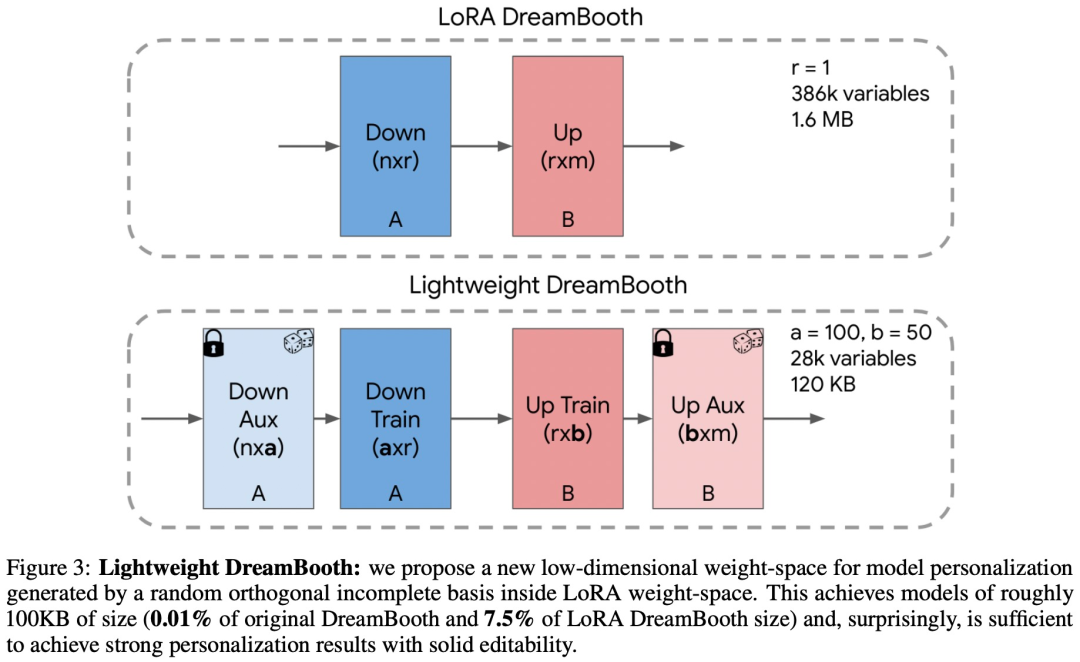
LiDB 的核心思想是进一步分解 rank-1 LoRa 残差的权重空间。具体来说,该研究使用 rank-1 LoRA 权重空间内的随机正交不完全基(random orthogonal incomplete basis)来实现这一点,如下图所示:
HyperDreamBooth 的训练和快速微调如下图 2 所示,分为两个阶段。
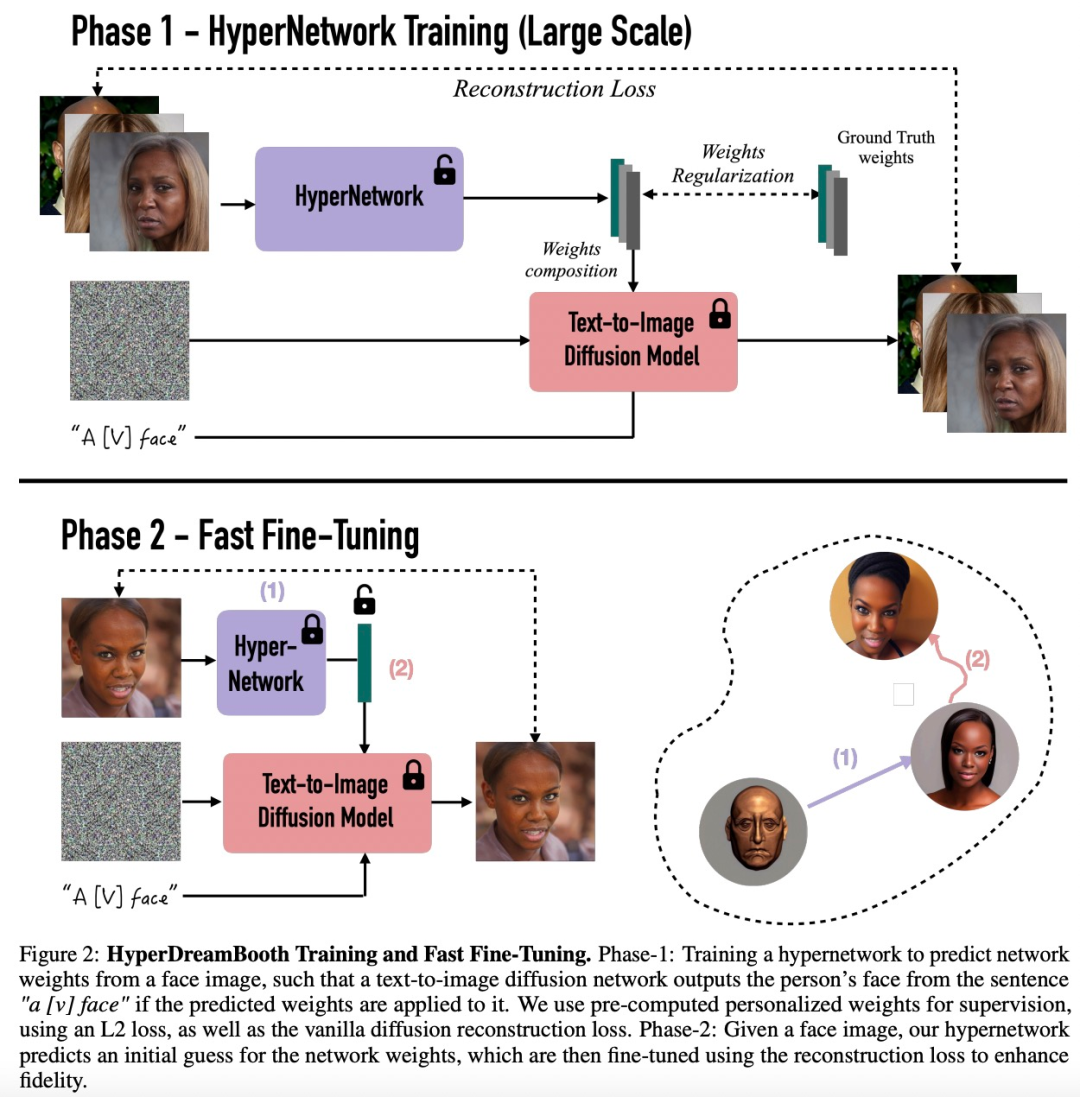
第 1 阶段:训练 HyperNetwork 以根据人脸图像预测网络权重。该研究使用预先计算的个性化权重进行监督,使用 L2 损失和 vanilla 扩散重建损失函数。第 2 阶段:给定面部图像,用 HyperNetwork 预测网络权重的初步猜测(initial guess),然后使用重建损失进行微调以增强保真度。
HyperNetwork 架构
该研究使用的 HyperNetwork 架构如下图 4 所示。其中,视觉 Transformer(ViT)编码器将人脸图像转换成潜在的人脸特征,然后将其连接到潜在层权重特征(初始化为 0)。Transformer 解码器接收连接特征的序列,并通过使用 delta 预测细化初始权重来迭代地预测权重特征的值。

值得一提的是,这是 transformer 解码器首次被用于 HyperNetwork。
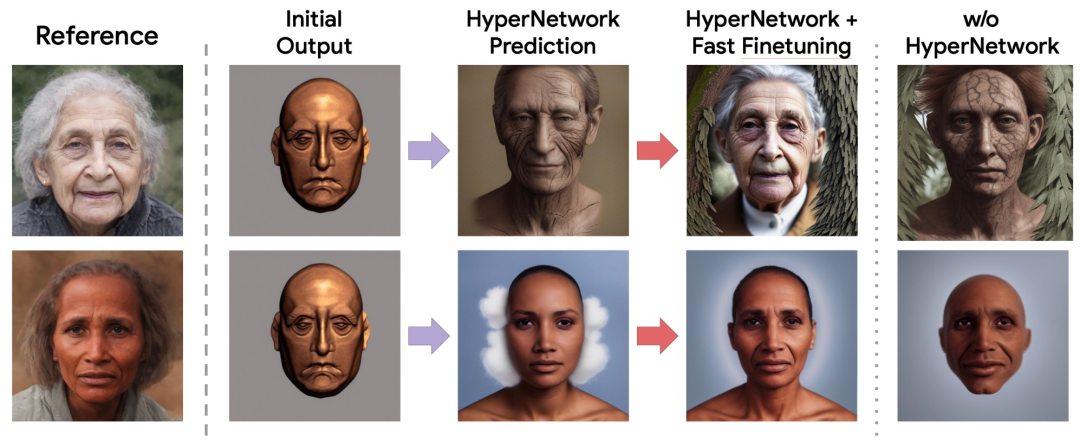
如下图所示,HyperNetwork + 快速微调取得了良好的效果:
实验
下表为 HyperDreamBooth 与 DreamBooth、 Textual Inversion 比较结果。表明,在所有指标上,HyperDreamBooth 得分最高。

下表为不同迭代次数下的比较结果,比较模型包括 HyperDreamBooth、DreamBooth、400 次迭代的 DreamBooth-Agg-1 和 40 次迭代的 DreamBooth-Agg-2。结果显示,HyperDreamBooth 在三项指标上都超过其他模型。

下表为消融实验结果:主要对比的是 HyperNetwork 对性能的影响。

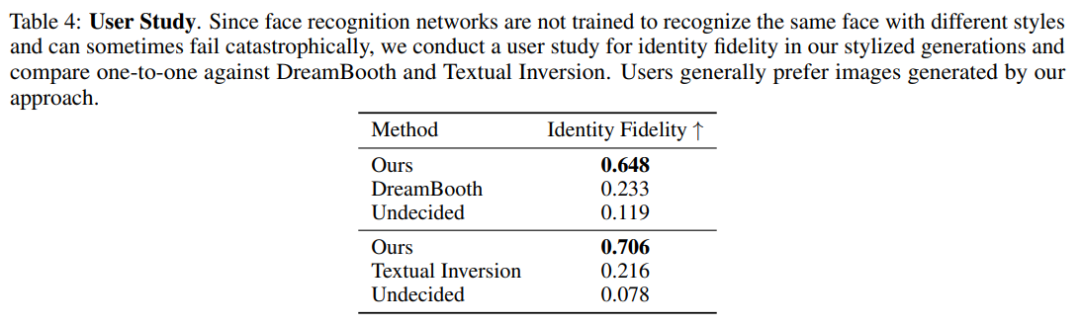
用户研究。该研究还让用户以投票的方式参与评估,结果显示用户对 HyperNetwork 生成的结果偏好强烈。
了解更多内容,请参考原论文。




