
LLM 微调不再头疼。
LLM 微调从一件复杂的事情,已经通过不断的技术改进变得易上手起来。
这不,免费且迅速的 LLM 微调已经可以实现了。
4 月底,斯坦福的一群开发者发布了 Lamini,号称可以为每个开发人员提供从 GPT-3 带到 ChatGPT 的超能力。
近日,Lamini 推出了全新的 Alpha 公测版,让微调上演「速度与激情」。现在只需十分钟、三至五行代码就能实现微调,更重要的是 0 费用。
目前,4 亿参数以内的 LLM 微调完全免费。这只是一个开始。
项目地址:https://github.com/lamini-ai/lamini
Lamini 的优势
先来一起看看 Lamini 有哪些优势。

免费,适用于小型 LLM;
迅速,10-15 分钟;
很大,无限大小的 prompt,比最大的 prompt 多 1000 倍以上的空间;
学习,检索增强生成,它不仅是在已知的基础上试图理解内容,还在学习新东西。
并且,在 Lamini 的项目地址中有着
1400 个问答数据集(这是关于 Lamini 的内部工程文档,你也可以将其自定义);
在此数据集上运行 LLM 微调的代码;
回答问题的开源微调 LLM(例如关于 Lamini,或其他你想问的)。
Lamini 使用教程
使用示例
Lamini 真的有这么神吗?这里由一份示例请你查收。
首先,有一个需要微调的 LLM。示例中是一个关于 Lamini 内部工程文档的问答式 LLM。

该模型提供了一个聊天界面,它使用了一个 410M 参数的 Pythia 模型作为基础。
这个 410M 参数 LLM 的性能看起来并不令人满意。当询问:「我如何向 Lamini 添加数据?」时,它给出的答案并不靠谱。

你还可以给它输入数据。对于本例,你有一个关于 Lamini 的 1400 个问题和答案的数据集。虽然它看起来很小,但它比目前最大的 Prompt 大小要大得多 (约 120K)。
以下是准备数据的专业建议:质量非常重要。只要 100 个高质量的例子就能让你走上正确的道路。那么什么是高质量?
高质量:连贯、清晰、准确的示例。
多样化:涵盖广泛的主题和数据范围,应避免虚假关联和数据偏差。
真实:实际的用户数据或人为创建的示例,而不是 LLM 生成的虚假示例,以捕捉人机交互的细微差别,并改进模型,使其超越现有的生成能力。
然后,只需将这些数据加载到模型中,并告诉它进行训练:

只需要 10-15 分钟,你就可以运行这个 LLM 了。
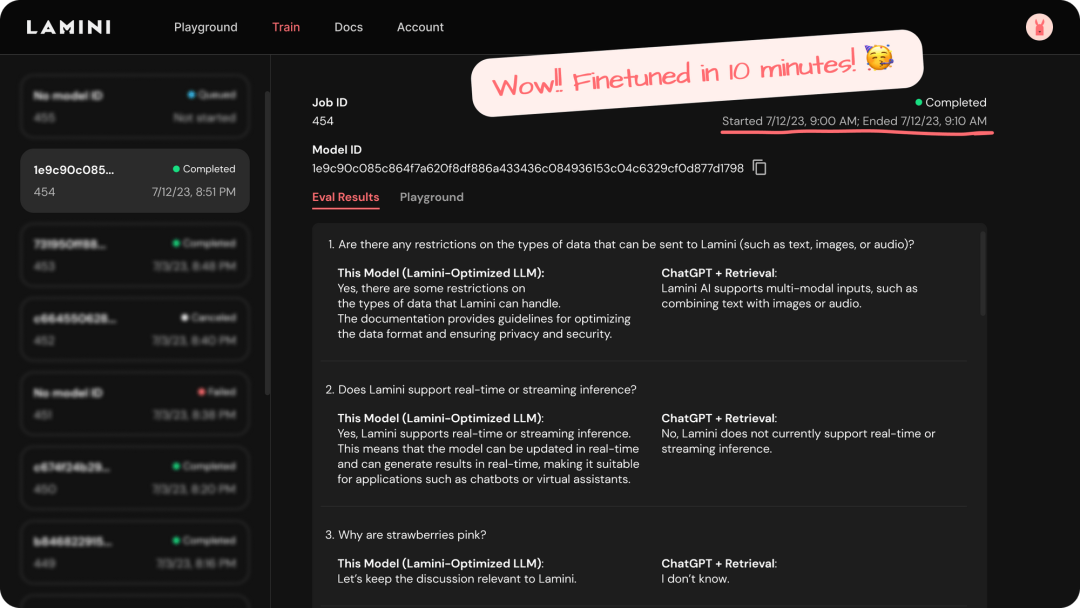
让我们再次问同样的问题,「我如何向 Lamini 添加数据?」,内容如下:

这次的答案是正确的了,看来微调发挥了显著的效果。
如何使用 Lamini 训练 LLM
1、使用 Lamini Types 定义 LLM 接口。你想让它成为一个聊天机器人?接口就是问进答出。你想让它成为代码 copilot?接口就是程序输入,更多程序输出。使用你的类型运行一般的 LLM(基本模型或基础模型)。
2、查找相关数据并创建 Lamini Types。哪些数据对执行任务的人类专家有用?获取该数据并创建与其模式相匹配的(附加)Lamini Types。它可以是支持性文档,如你的文档中的函数,用于你的代码聊天机器人,也可以是向你的机器人提出的示例问题。
3、使用 Lamini 将数据加载到 Types 中,并将 Types 加载到 LLM 中。这将你的数据转换为 Types 格式,以便 LLM 能够最好地从中学习。
4、获取与你的 LLM 接口相匹配的数据。如果没有?也没问题。这就是数据生成的目的,其中利用 LLM 管道。首先,使用 Lamini LLM Engine 运行数据生成,以获得更多正确的 Lamini Types(任何一种)数据。然后使用 Lamini 过滤器或你自己的脚本过滤数据,以获得高质量数据。
5. 通过优化训练使通用 LLM 专业化。使用 Lamini 库,针对所有数据训练你自己的 LLM。

参考链接:
https://twitter.com/realSharonZhou/status/1679212309938593797

